| id | headcircumference | length | Birthweight | Gestation | smoker | motherage | mnocig | mheight | mppwt | fage | fedyrs | fnocig | fheight | lowbwt | mage35 | LowBirthWeight | QCL_1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1313 | 12 | 17 | 5.8 | 33 | 0 | 24 | 0 | 58 | 99 | 26 | 16 | 0 | 66 | 1 | 0 | Low | 1 |
| 1 | 431 | 12 | 19 | 4.2 | 33 | 1 | 20 | 7 | 63 | 109 | 20 | 10 | 35 | 71 | 1 | 0 | Low | 1 |
| 2 | 808 | 13 | 19 | 6.4 | 34 | 0 | 26 | 0 | 65 | 140 | 25 | 12 | 25 | 69 | 0 | 0 | Normal | 2 |
| 3 | 300 | 12 | 18 | 4.5 | 35 | 1 | 41 | 7 | 65 | 125 | 37 | 14 | 25 | 68 | 1 | 1 | Low | 1 |
| 4 | 516 | 13 | 18 | 5.8 | 35 | 1 | 20 | 35 | 67 | 125 | 23 | 12 | 50 | 73 | 1 | 0 | Low | 2 |
Lab 4
1 Linear Regression
Recall that the linear regression provides the “best line” that reflects the relation between two sets of data. Namely, let \(X=(x_1,\ldots,x_n)\) and \(Y=(y_1,\ldots,y_n)\) be vectors (arrays) of data. We define
\[ \begin{aligned} \bar{x}& = \frac1n \sum_{i=1}^n x_i,\\ S_{xx} &= \sum_{i=1}^n(x_i-\bar{x})^2=\sum_{i=1}^nx_i^2-n\bar{x}^2,\\ S_{xy}&=\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})=\sum_{i=1}^nx_iy_i-n\bar{x}\bar{y},\\ S_{yy}&= \sum_{i=1}^n(y_i-\bar{y})^2=\sum_{i=1}^ny_i^2-n\bar{y}^2. \end{aligned} \]
Then the best fit line is
\[ \hat{y}=\hat{\beta}_0+\hat{\beta}_1 x, \]
where
\[ \begin{aligned} \hat{\beta}_1 &= \dfrac{S_{xy}}{S_{xx}},\\ \hat{\beta}_0 &= \bar{y}-\hat{\beta}_1\bar{x}. \end{aligned} \]
The strength of a linear relationship between the variables can be measured by the Pearson correlation coefficient (or just the correlation coefficient) which is given by
\[ r=\dfrac{S_{xy}}{\sqrt{S_{xx}S_{yy}}}. \]
We know that \(-1\leq r\leq 1\) and we say that
\[ \begin{aligned} |r|>0.7 & \quad \text{means strong correlation}\\ 0.7\geq |r|>0.4& \quad \text{means moderate correlation}\\ |r|\leq 0.4 & \quad \text{means weak correlation} \end{aligned} \]
1.1
Download file Birthweight.csv and upload it to Anaconda.com/app. Assign it to the dataframe named df. Show the first rows of df.
Hint: to import CSV file, use commands discussed in Lab 1. Don’t forget about pandas library.
You should get the following output
As you can see, this dataframe contains the data about newborns and their parents. (Here values of headcircumference and length are in inches and Birthweight is in pounds.)
We will study dependence of newborn’s weights on their lengths.
1.2
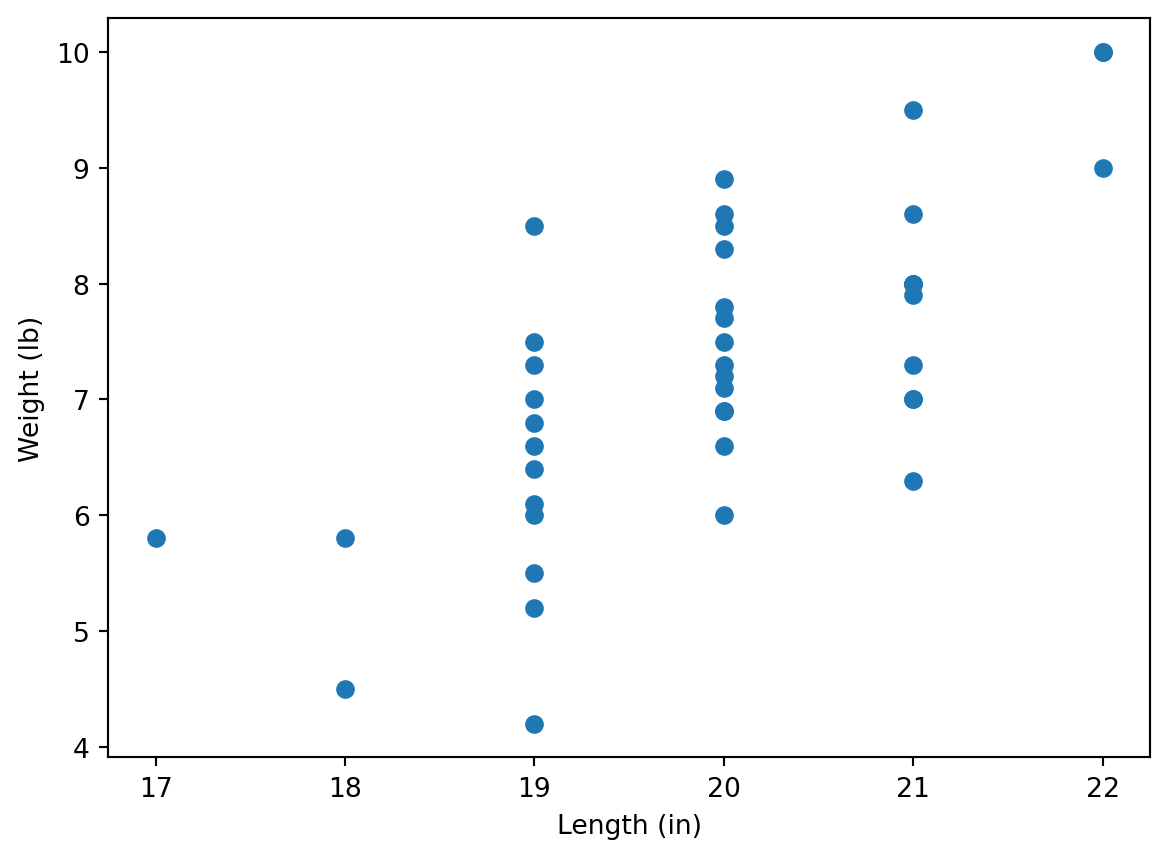
Plot a scatter plot making length data on the horizontal axes and Birthweight data on the vertical axes. Label axes appropriately, and show in labels the units (in and lb).
Hint: use commands discussed in Lab 3. Don’t forget about matplotlib.pyplot module. Note also that matplotlib allows to use Pandas series (e.g. dataframe columns), it’s not necessary to convert them into Numpy arrays using .to_numpy() command.
Manual calculation
At first, we calculate the regression line manually, using the formulas above.
1.3
Convert columns length and Birthweight to Numpy arrays x and y, respectively. Assign \(\bar{x}\) and \(\bar{y}\) to mx and my, respectively. Note that you may use either mean or np.mean functions.
Check your answer:
[mx, my][19.928571428571427, 7.264285714285713]1.4
Assign values of \(S_{xx}, S_{xy}, S_{yy}\) to variables sxx, sxy, and syy, respectively (use the formulas at the beginning of this Lab). Note that you can use functions sum or np.sum, and remember about vector operations in Python.
Check the answer:
[sxx, sxy, syy][50.785714285714285, 42.292857142857144, 72.49642857142857]1.5
Assign values of \(\hat{\beta}_1\) and \(\hat{\beta}_0\) to variables b1 and b0, respectively. Assign the Pearson regression coefficient to variable r. (To find the square root, you may use np.sqrt function.)
Check the answer:
[b0, b1, r][-9.331645569620253, 0.8327707454289733, 0.6970082792022007]Linregress function
Instead of all these calculations, we can also use linregress class from scipy.stats module:
from scipy.stats import linregress
linregress(x,y)LinregressResult(slope=0.8327707454289743, intercept=-9.331645569620274, rvalue=0.697008279202201, pvalue=2.9301969030655954e-07, stderr=0.13546119087983002, intercept_stderr=2.7036545086005135)You may notice that it gives the same answers (up to a little calculation error), where slope stands for b1 (that is indeed the slope of \(\hat{y}=\hat{\beta}_0+\hat{\beta}_1 x\)), intercept stands for b0, and rvalue stands for r. You may access these values as follows:
lr = linregress(x,y)
[lr.intercept, lr.slope, lr.rvalue][-9.331645569620274, 0.8327707454289743, 0.697008279202201]that is pretty simular to [b0, b1, r] calculated before.
We are going now to draw now the graph of the regression line on the scatter plot. For this, we create an array of values on the horizontal axes by dividing the interval between min(x) and max(x) by e.g. \(100\) parts (for this we will use np.linespace function), and calculate the values of the linear regression line at these points:
import matplotlib.pyplot as plt
xvalues = np.linspace(min(x), max(x), 100)
yvalues = lr.intercept + lr.slope * xvalues
plt.plot(xvalues, yvalues, color = 'r')
plt.show()
1.6
Combine the regression line with the scatter plot to get the following output:
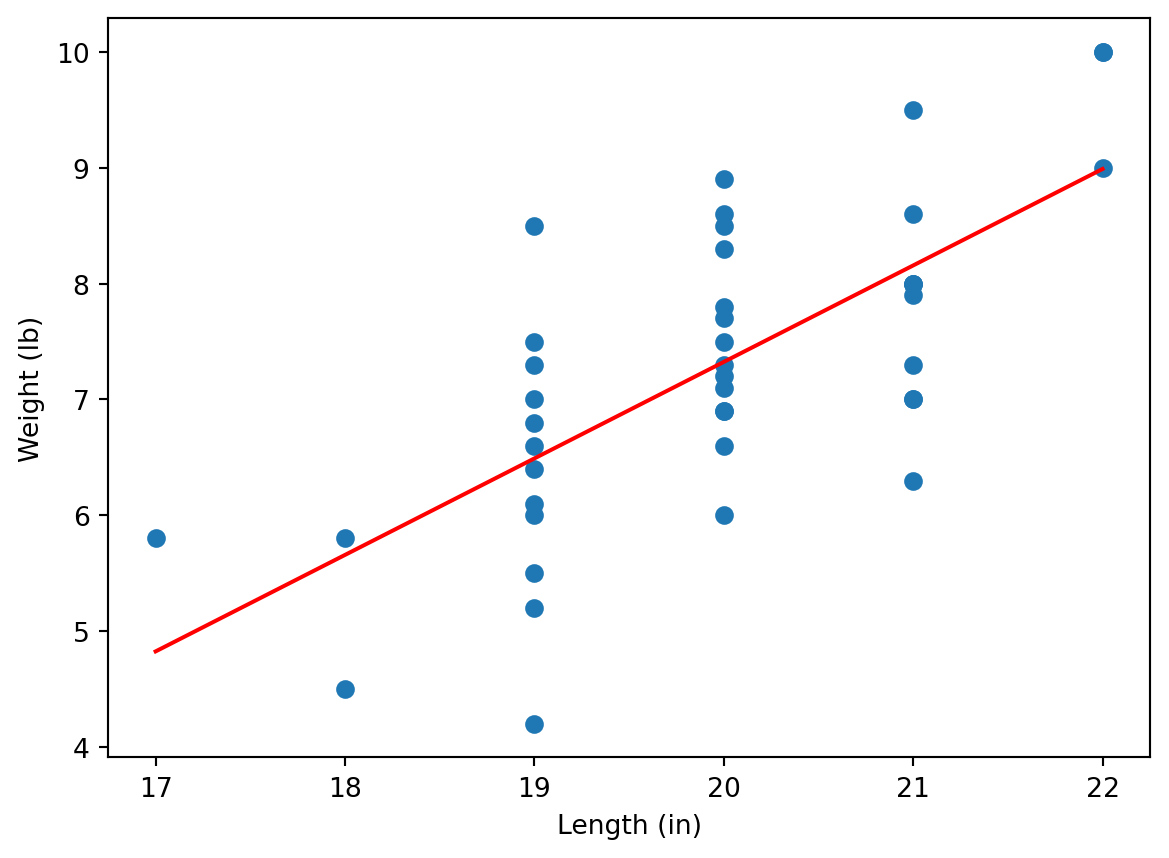
As we can see, the regression line reflects the trend between weights and lengths, however, the values are “jumping” around the line. We could see that the correlation coefficient (see lr.rvalue or r) is not large:
lr.rvalue0.697008279202201i.e. we see here a moderate correlation.
1.7
Download now file Experience-Salary.csv which contains data on how the salary depends on experience. Repeat the previous steps to show the scatter plot together with the regression line:
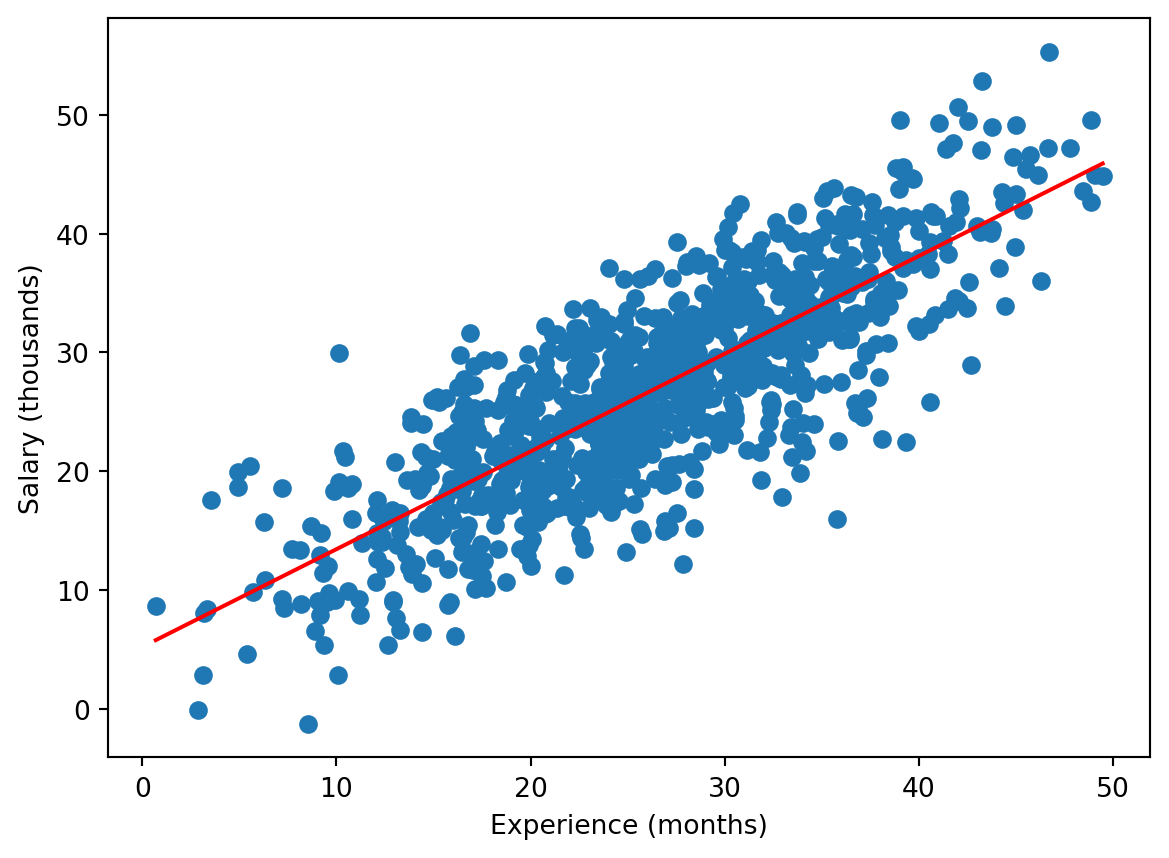
You can see that here the regression line fits the data better. Indeed, in this case the correlation is higher:
lr.rvalue #If you kept the notation lr for linregress object.0.81096929458406552 (Binary) Logistic Regression
In contrast to the linear regression, the binary logistic regression can be applied if the dependent variable takes only two values, e.g. \(0\) and \(1\). For example, download file colleges.csv and upload it to Anaconda.com/app.
Investigating data
df = pd.read_csv("colleges.csv")
df.tail()| gmat | gpa | work_experience | admitted | |
|---|---|---|---|---|
| 25 | 650 | 3.7 | 6 | 1 |
| 26 | 670 | 3.3 | 6 | 1 |
| 27 | 690 | 3.7 | 5 | 1 |
| 28 | 690 | 3.7 | 5 | 1 |
| 29 | 620 | 2.7 | 5 | 0 |
This dataset describes how much the marks in gmat and gpa exams (read Wikipedia for details about these exams, it’s not relevant now though) and work_experience affect whether a student was admitted to a US college.
Note that we used here tail function, it shows the last rows of a dataframe. Note that the last index is 29 i.e. the dataframe contains 30 rows (the indexes start with 0 as usual). Another way to get the dimensions of the dataframe is
df.shape(30, 4)i.e. there are 30 rows and 4 columns.
As you can see, the admitted column contains only \(0\) and \(1\), where \(1\) stands for admission, and \(0\) for failure; more precisely, we can see this for the last rows only, but we can check this using the following Python trick:
set(df['admitted']){0, 1}Here set function returns the set of all values of the column (unique values as it is a set). An alternative Pandas code for this is
df['admitted'].unique()array([0, 1], dtype=int64)Separating data
Now we save the last row in a separate dataframe, call it df_test, and redefine df as the first 29 rows of the original df (you learned the functions below in Python lectures of MA-M26).
df_test = df.iloc[-1]
df = df[:-1]We can check that now
df.tail()| gmat | gpa | work_experience | admitted | |
|---|---|---|---|---|
| 24 | 690 | 3.3 | 3 | 0 |
| 25 | 650 | 3.7 | 6 | 1 |
| 26 | 670 | 3.3 | 6 | 1 |
| 27 | 690 | 3.7 | 5 | 1 |
| 28 | 690 | 3.7 | 5 | 1 |
i.e. df contains 29 rows only, and
df_testgmat 620.0
gpa 2.7
work_experience 5.0
admitted 0.0
Name: 29, dtype: float64In particular, the student stored now in df_test was not admitted.
Logistic regression for 1 independent variable
We first study how much the mark in gmat affects the admission. We use the following code:
import statsmodels.formula.api as smf
reg = smf.logit('admitted ~ gmat', data = df).fit()
reg.summary()Optimization terminated successfully.
Current function value: 0.485467
Iterations 6| Dep. Variable: | admitted | No. Observations: | 29 |
|---|---|---|---|
| Model: | Logit | Df Residuals: | 27 |
| Method: | MLE | Df Model: | 1 |
| Date: | Wed, 22 Oct 2025 | Pseudo R-squ.: | 0.2990 |
| Time: | 00:15:07 | Log-Likelihood: | -14.079 |
| converged: | True | LL-Null: | -20.084 |
| Covariance Type: | nonrobust | LLR p-value: | 0.0005289 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -17.6764 | 6.763 | -2.614 | 0.009 | -30.932 | -4.421 |
| gmat | 0.0272 | 0.010 | 2.644 | 0.008 | 0.007 | 0.047 |
It contains a lot of data, we actually need only the values of coef at the bottom part: we want to get (see Lecture Notes)
\[ \mathrm{logit} (p) = \hat{\beta}_0 + \hat{\beta}_1 x_1 \]
(here there is only one independent variable, gmat, hence, we use only \(x_1\)), and the values of coef in the summary for Intercept is \(\hat{\beta}_0\), whereas the value of gmat in the summary is \(\hat{\beta}_1\). We can access these values directly:
[reg.params.iloc[0], reg.params.iloc[1]][-17.67642930546272, 0.027183426815336253]Now, we are going to demonstrate the obtained result graphically. We know that (see Lecture Notes)
\[ p = \frac{e^{\hat{\beta}_0+\hat{\beta}_1 x_1}}{1+e^{\hat{\beta}_0+\hat{\beta}_1 x_1}} \]
We are going now to plot the scatter plot of admitted vs gmat and plot on the same diagram the curve \(p=p(x_1)\). We will use np.exp function for the exponent.
x1 = df['gmat'].to_numpy()
p = df['admitted'].to_numpy()
plt.scatter(x1, p)
b0 = reg.params.iloc[0]
b1 = reg.params.iloc[1]
x1values = np.linspace(min(x1), max(x1), 100)
pvalues = np.exp(b0 + b1 * x1values)/(1 + np.exp(b0 + b1 * x1values))
plt.plot(x1values, pvalues, color = 'r')
plt.show()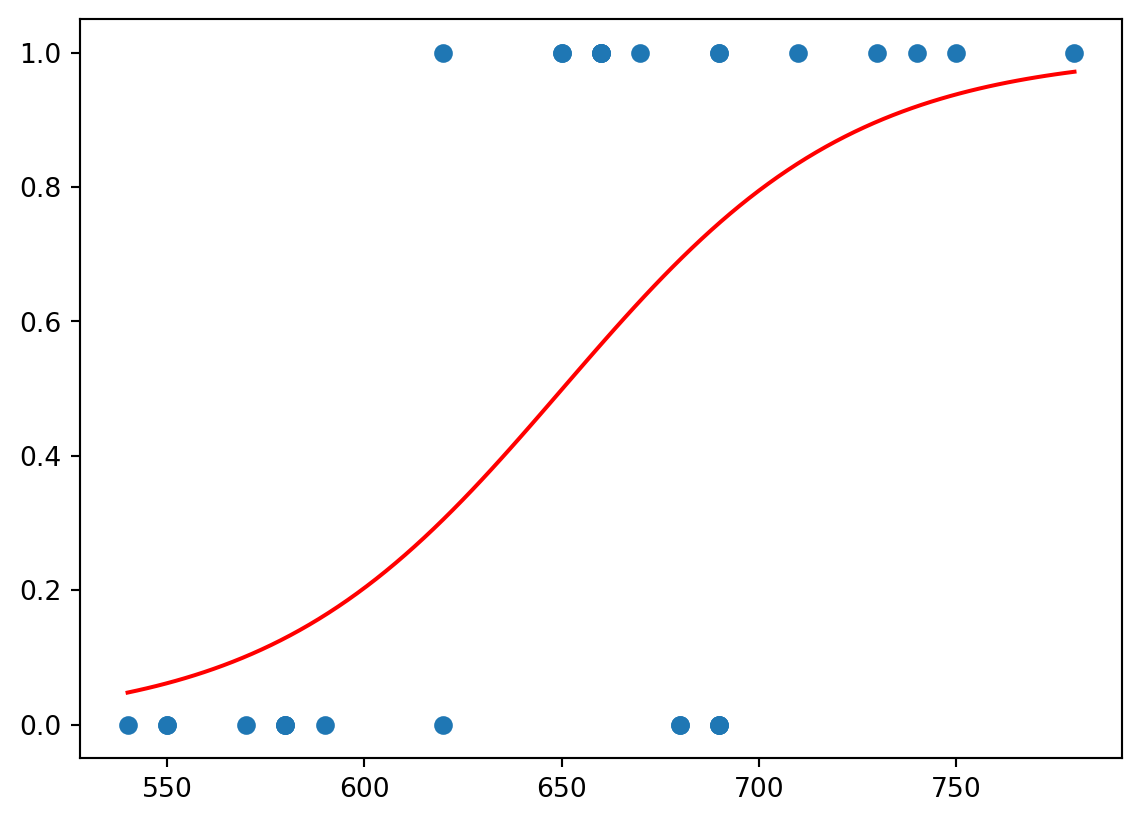
We can see that the red function separates values of \(0\) and \(1\).
This function can be used to make predictions about the admission. Namely, we take the value of gmat for the last student of the original dataframe, now stored in the separate dataframe df_test; and then we calculate \(p\) at this \(x_1=\)gmat:
gmat = df_test['gmat']
np.exp(b0 + b1 * gmat)/(1 + np.exp(b0 + b1 * gmat))0.30518983321629944The received value is more close to \(0\) then to \(1\), hence, we may expect that the student would not be admitted; that was the case. Though the value is still relatively large, hence, probably, one mark is not enough to make a good prediction.
Logistic regression for 2 independent variables
However, we expect that the admission depends on both marks, in gmat and in gpa. To take both marks into account one needs to change admitted ~ gmat by admitted ~ gmat + gpa in the previous code.
2.1
Change the code as explained and get the following summary.
Optimization terminated successfully.
Current function value: 0.322141
Iterations 8| Dep. Variable: | admitted | No. Observations: | 29 |
|---|---|---|---|
| Model: | Logit | Df Residuals: | 26 |
| Method: | MLE | Df Model: | 2 |
| Date: | Wed, 22 Oct 2025 | Pseudo R-squ.: | 0.5348 |
| Time: | 00:15:07 | Log-Likelihood: | -9.3421 |
| converged: | True | LL-Null: | -20.084 |
| Covariance Type: | nonrobust | LLR p-value: | 2.162e-05 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -22.0171 | 9.232 | -2.385 | 0.017 | -40.111 | -3.923 |
| gmat | 0.0150 | 0.014 | 1.052 | 0.293 | -0.013 | 0.043 |
| gpa | 3.7604 | 2.003 | 1.877 | 0.060 | -0.166 | 7.686 |
Again, the coefficients are available using (in the previous notations) reg.params. As before, Intercept stands for \(\hat{\beta}_0\), gmat stands for \(\hat{\beta}_1\), and also gpa stands for \(\hat{\beta}_2\) in
\[ \mathrm{logit} (p) = \hat{\beta}_0 + \hat{\beta}_1 x_1 + \hat{\beta}_2 x_2 \]
and hence
\[ p = \frac{e^{\hat{\beta}_0+\hat{\beta}_1 x_1+\hat{\beta}_2 x_2}}{1+e^{\hat{\beta}_0+\hat{\beta}_1 x_1+\hat{\beta}_2 x_2}} \]
We can show how \(p\) separates the values (some lines of the code may be new for you - it’s just for your information, you are not required to learn them):
x1 = df['gmat'].to_numpy()
x2 = df['gpa'].to_numpy()
p = df['admitted'].to_numpy()
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1, projection='3d', computed_zorder=False)
x1values = np.linspace(min(x1), max(x1), 100)
x2values = np.linspace(min(x2), max(x2), 100)
[X1, X2] = np.meshgrid(x1values, x2values)
b0 = reg.params.iloc[0]
b1 = reg.params.iloc[1]
b2 = reg.params.iloc[2]
pvalues = np.exp(b0 + b1 * X1 + b2 * X2)/(1 + np.exp(b0 + b1 * X1 + b2 * X2))
ax.plot_surface(X1, X2, pvalues, color = 'r', alpha = 0.4)
ax.scatter(x1, x2, p)
plt.show()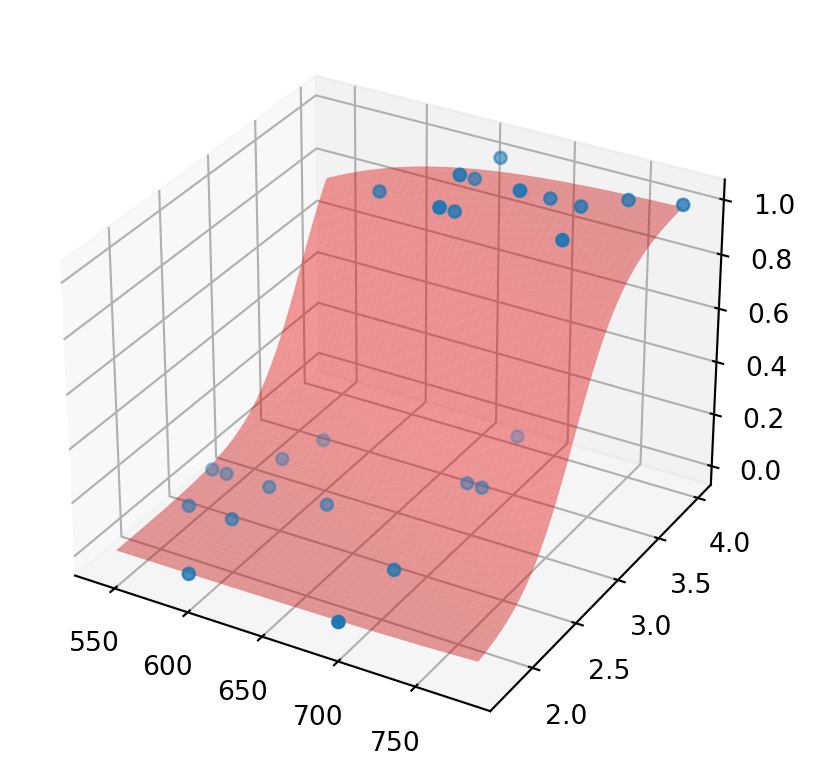
As you can see, the red graph (surface) of \(p\) separates values of \(0\) and \(1\). Again, we may try to predict the admission for the student with data stored in df_test. We assigned to gmat the corresponding mark, now we do the same for gpa and calculate p for these two values. As you can see, the result is much closer to \(0\), hence, we are more confident in our (correct) prediction that the student would not be admitted.
gpa = df_test['gpa']
np.exp(b0 + b1 * gmat + b2 * gpa)/(1 + np.exp(b0 + b1 * gmat + b2 * gpa))0.07118806995711167Logistic regression for 3 independent variables
Now, we consider the dependence of admitted on all three values: gmat, gpa, and work_experience. Surely, in this case, we will not be able to draw \(p\) (as it would be a 4-dimensional diagram), but we can calculate \(\hat{\beta}_0,\hat{\beta}_1,\hat{\beta}_2,\hat{\beta}_3\).
2.2
Find the coefficients of
\[ \mathrm{logit} (p) = \hat{\beta}_0 + \hat{\beta}_1 x_1 + \hat{\beta}_2 x_2 + \hat{\beta}_3 x_3 \]
Optimization terminated successfully.
Current function value: 0.255306
Iterations 8Check your answer:
reg.paramsIntercept -16.182243
gmat 0.002624
gpa 3.258770
work_experience 0.994371
dtype: float642.3
Assign to w_exp the work experience value for the student from df_test and calculate the function
\[ p = \frac{e^{\hat{\beta}_0+\hat{\beta}_1 x_1+\hat{\beta}_2 x_2+\hat{\beta}_3 x_3}}{1+e^{\hat{\beta}_0+\hat{\beta}_1 x_1+\hat{\beta}_2 x_2+\hat{\beta}_3 x_3}} \]
for that student. Check the answer:
0.31333312863167756As you can see, the information about a relatively high work experience (5 years in this case), increased chances to be admitted, though the non-admission is still more likely.
Note that the rest of information from summary actually explains the level of certainty we may have in the future prediction (we do not consider this now). Note also that, in practice, one predicts outcomes for a number of students (the dataframe df_test would contain a lot of rows), and the prediction is “good” if one predicted correctly for a big percentage of them.